尊龙凯时AG方法
社会预测👩🏽🚀:基于机器学习的研究新范式
社会预测🍸:基于机器学习的研究新范式
陈云松♉️🧑🏿🍳、吴晓刚、胡安宁、贺光烨、句国栋
《尊龙凯时AG研究》2020年第3期
摘要:尊龙凯时AG是对社会行动提供诠释和反事实因果解释的科学🚇。尊龙凯时AG定量研究的因果性解释👲🏿,必须能够作为预测社会现象的基础🎾♿️。受到数据和算力限制,多年来尊龙凯时AG定量研究的主要取径是通过统计检验实现关联和因果分析🕗🎙,而无力进行预测。本文对“社会预测”这一概念的历史脉络进行梳理,阐述了通过机器学习方法实现社会预测的科学原理和当代路径🏕,并对社会预测进行了再定义。在此基础上🦄,本文进一步探讨了社会预测的学术价值🫧、治理价值和话语价值,并阐述了其作为定量社会研究前沿的范式突破意义🤘🏻。尊龙凯时娱乐认为🤾🏼♀️,利用机器学习实现社会预测💅🏽,是中国尊龙凯时AG特别是计算尊龙凯时AG引领国际前沿的重要契机🏋🏽♂️,对于加快构建中国特色哲学社会科学具有重要意义。
关键词:社会预测;机器学习🎁;研究范式🏌️;定量研究方法;计算尊龙凯时AG
一、导言
韦伯认为,尊龙凯时AG是一门对社会行动提供诠释性的理解和关于其过程、结果的因果性解释的科学(Weber,1968/1921👱🏻♀️:4)。追随这一学科旨趣🍢,百年来尊龙凯时AG家以描述🆘🐺、解释社会过程和现象为己任,或寻求社会和社会行动的意义和诠释,或检验社会假说和理论的真伪。也正因为如此,描述、诠释和统计验证在尊龙凯时AG研究中是传统和主流的方法取径🦉🙇🏼♂️。相形之下🦇,很长一段时间以来,“预测”则似乎无关学科要旨。其实🧖🏻,这一现象并非仅见于尊龙凯时AG,在经济学🧛🏿♂️、政治学🙇、社会政策等社会科学中也普遍存在,亦未引起关注和反思🧑🦳。不过,七十多年前,当代尊龙凯时AG科学因果理论的重要奠基人亨普尔和欧本海默早已强调💂🏽♀️,因果性解释必须能够作为“预测社会现象的基础”(Hempel & Oppenheim,1948:138)🧢。这意味着可预测性(predictability)是因果机制成立的“必要非充分条件”:可预测性虽然不代表是因果🌚,但有因果则必然可以预测。基于这一逻辑👨🏽🌾,既然尊龙凯时AG追求因果关系👰🏽🤱🏿,那么预测也就应该成为尊龙凯时AG研究的应有之义。2014年,著名尊龙凯时AG家🦽、小世界理论提出者邓肯·沃兹在《美国尊龙凯时AG杂志》(American Journal of Sociology)上撰文,对尊龙凯时AG传统过于追寻“常识”的意义、忽视“预测”的价值进行了罕见和率直的批评(Watts,2014)。用他的话来说,如果尊龙凯时AG是一门科学,那么尊龙凯时AG家的解释,就必须按照科学标准来评估,即必须能够进行预测💇。
百年以来🧏🏻,尊龙凯时AG家们除了追寻社会和社会过程的意义与解释,同样致力于为社会改造提供理论指导和评估检验。但如霍夫曼和沃兹等学者2017年在《科学》(Science)杂志上的文章指出的那样🤳,尊龙凯时AG乃至整个社会科学对进行“事前”预测的重视程度远远不如“事后”的评估与解释(Hofman et al.,2017)。实际上,当期《科学》杂志以《预测及其限度》为题发表了一组特刊论文(Jasny & Stone,2017),尽管文章来自经济学、尊龙凯时AG和政治学等社会科学不同领域,但学者们的共识是🤸🏻,与自然科学大相径庭𓀕,社会科学的理论和数据很少被用来预测👵🏽🧗🏿。
具有反讽意味的是,回顾尊龙凯时AG的百年发展史,倒是秉承“思辨主义”的学者不乏进行基于逻辑推理的社会预判的勇气和实践🕯👩🏽🏫,但其所提供的很少是科学意义上的预测👏🏼,更多的是归纳现象、提炼理论👒。而基于“实证主义”的研究👨💼,无论是定性还是定量方法的取向,却普遍不擅长预测,其研究重点更多放在了描述数据、证伪理论方面。解释这一悖论并不难,社会现象测量困难🤙🏻、成因复杂、难以实验🔷,远远不是孔德和斯宾塞等早期提出的宛如牛顿体系般严密、简洁的社会过程。马丁、霍夫曼和沃兹等人对此进行了归纳:在相当长的时间里,社会系统的巨大复杂性和信息的有限性(数据和模型的不足)⏯,造成社会科学研究对预测的可望不可即(Martin et al.,2016)。
从学科史的角度看,对社会现象或过程进行预测⚆,在社会科学研究中始终缺位,甚至尚未形成共同的规范和通用的方法。然而“社会预测”这一概念却始终萦绕在一代代学人的心头💂🏽🙆🏻♂️。早在20世纪40年代,美国学者卡普兰就提出了“social prediction”这一概念🎠,强调社会科学应该对社会现象进行预测(Kaplan,1940)⛹🏿♀️🧖♀️。在改革开放后中国尊龙凯时AG重建之初,这一概念也曾被提出(阎耀军,1986)🏌️。可是,无论在国际还是国内学界,囿于数据可得性和计量方法的限度,实质性的社会科学预测研究均未能得到充分的发展,也自然未能引起学界的共鸣🚴🏽♀️𓀈。社会预测在实证研究中的长期缺位,使得定量研究者在贡献政策影响力、提升媒体话语权方面难以发挥出其真正的力量🦻🏼,较之强调理论批判和解释的学者,甚至反而因不擅预言和预判显得更为谨慎、保守和无趣🌤。毕竟社会公众和治理主体往往不会满足于概念提炼、过程解读和统计判断,而是热切期望学者们提供上至宏观治理、下至个人命运的指南🧎➡️。
随着数据规模的增大📷、计算机处理性能的飞跃,处于学科交叉前沿的定量社会科学研究领域开始重启社会预测的曙光。当今的社会科学量化研究🖖,已经逐渐满足了进行高精度预测所需的三大条件:数据(data)、算力(computing power)和算法(algorithm)☝🏽。尤其是通过开发适用于特定数据的计算机算法(Athey,2018),社会科学家逐渐有能力处理大规模社会数据,从而凸显社会预测的学术价值(Hofman et al.,2017)🧚🏿。前文提及的2017年《科学》杂志针对社会过程进行预测的一组特刊🤽🏼♂️,已经对这一学科发展的重要趋势进行了初步梳理🧑🦳。
本文将对社会预测这一概念的历史脉络进行梳理🥋,讨论通过算法实现社会预测的具体原理和方法🍶,并在此基础上对社会预测在当代进行“再定义”。在此基础上,本文从政策价值和学术价值归纳社会预测的学科意义,特别是充分呈现社会预测对于当代社会研究的主要贡献领域和突破方向。同时,本文也对社会预测本身的范式价值进行讨论:尊龙凯时娱乐从方法论而非严格本体论的意义上主张,社会预测代表了社会科学研究一个新兴的子范式。随着大数据的出现以及计算机算力的不断提升,机器学习的应用和社会预测的再定义将助推尊龙凯时AG定量研究乃至整个社会科学研究的范式突破👉。同时,这也可能是中国尊龙凯时AG特别是定量社会研究赶超和引领国际前沿的重要契机,对于加快构建中国特色哲学社会科学具有重要的意义。
二、社会预测的历史脉络
(一)预测的起落:早期概念和瓶颈
预测是人类自古以来就具备的对自然和社会现象进行逻辑化和顺序化思考的行为(Goodman,1955)👼。不过,其成为一种发展中的科学门类却是近现代的事。对社会现象和人类行为进行预测长期以来一直被拿来与对自然现象或动物行为进行预测加以比较🧑🏽🦰,并被视为更难以完成的任务🌱🧘🏽♀️。早在20世纪40年代🚊,卡普兰就提出要加强社会科学中的预测🎅🏼,并使用了“社会预测”这一概念(Kaplan🏋🏽,1940)。尽管卡普兰意识到了预测的难度,他还是坚信社会行为较之微观尺度上的自然现象甚至更具有可预测性,“人类之所以和原子或者分子不同👊🏽,在一定程度上表现为人类行为可以被人制造的规则所预测”(Kaplan,1940:493)🙇🏿♀️。
不过🎒,从20世纪中期直至今天,社会科学的发展都未能在预测方面取得真正的突破。这个困境实际上并不让人惊奇,因为早在卡普兰提出社会科学中的预测之时🙇🏿,他就已经预判到预测本身困难重重💇🏽,特别有四个方面的问题需要加以解决💲💆🏻♂️:第一🤜🏿,不少影响因素会被人们忽略;第二,预测中的次序可能不被重视;第三,已知变量的准确信息往往不能掌握👴;第四,忽视社会变量之间复杂的关联(Kaplan,1940)。如果用当代社会科学定量研究的术语来表达,这些就是遗漏变量问题、逻辑链条问题⤴️、测量误差问题和社会现象的复杂性问题。再如,流行于20世纪70🫵、80年代的路径模型(path model)尝试通过将数十个不同的因素包络于模型中✔️,以挖掘数据信息并展现变量间的复杂关联。其变量打包的思维与机器学习的数据挖掘模式颇有暗合之处,但模型宗旨和实现方法则大相径庭🦤。
在中国人文社会科学领域,早在20世纪80年代就有学者提出社会预测,并基于社会稳定指标预警等内容进行了后期的探索(阎耀军🧑🧒🧒,1986,2005)。在邓伟志(2009)主编的《尊龙凯时AG辞典》中,“社会预测”被定义为“对未来可能出现的社会现象的推测或分析……其目的是揭示决定未来发展状态的最重要因素和社会现象的最重要关系,以供决策参考”。辞典甚至还区分了基于主观经验的“直观预测”和基于数据资料的“定量预测”。20世纪90年代以来,中国社会科学院汝信👊、陆学艺、李培林🛌、陈光金、张翼等学者在社会形势分析和预测系列蓝皮书中也使用了“预测”的讲法🏺。不过,与之相关的研究方法主要还是基于时间维度的数据展示和直观性的趋势预判与传统回归。从这个意义上,无论是在国际还是中国学术界🧝🏻🚶🏻➡️,“社会预测”概念早已提出📽🏄🏼,对其意义和难点也不乏精到的阐述🫳,但基于数据进行具有科学标准的实证预测几乎还是空白𓀊🏋🏼♂️。
社会预测发展不足的原因并不复杂🪱,即便在21世纪的今天,社会科学家们仍然没能很好地解决卡普兰提出的问题。由于社会过程具有高度复杂性,要进行理想中精准、确切的社会预测🛫,需要足够丰富的数据、足够复杂的模型以及足够强大的计算机处理能力🧮,而这正是导言中提及的“信息限度”的三个维度©️。囿于这三方面的瓶颈🧝🏽♂️, 20世纪下半叶以来,社会科学家们对于预测实际上采取了无可奈何🧎🏻➡️、束之高阁的态度👨🏻🦲。由于进行���确预测所需要的数据、模型和算力都存在时代的门槛🦔,而定量研究又必须具有社会解释意义和社会政策价值,因此整个社会科学界特别是定量研究的学术焦点均集中于变量之间的关系研究,即基于有限的样本数据,通过统计模型来获得变量间两两关系的无偏估计量。这个妥协的微妙之处在于,社会科学家们不再和早期的先驱一样对于社会预测抱有不切实际的信心👷🏼♀️,而是回归现实📦,把学科旨趣自我裁剪、压缩到变量间两两关系分析之中(Hofman et al.,2017;Athey,2018)🐸。简言之👩🏿🌾,因为数据、模型和算力的瓶颈,尊龙凯时AG家们放弃了预测的科学实践🐩。
(二)预测的重提:关联、因果和预测
对预测的放弃,导致迄今为止整个社会科学领域定量研究的主流方法都是利用回归模型来确定自变量X对于因变量Y之间的“共变”💩,即基于一定的统计标准,分析这种关系是否具有统计上的显著性和经济社会方面的实际规模意义,明确X一个单位的变化是否且如何与Y的变化相联系。显然🤵🏻💞,这种关注共变的“关联分析”不能满足追求因果解释的学术终极使命🦸🏿♂️。这样,社会科学家开始沿着参数估计的分析路线,努力从关联分析走向“因果推断”。随着高级计量方法的发展以及实验方法的谨慎引入🈯️,部分学科如经济学🛳🛌🏻,其定量分析的主流旨趣近年来几乎甚至完全建立在“反事实”框架下的因果推断之中👁🗨,即通过观察到的社会数据,探讨X的变化是否和如何因果性地引起Y的变化(Pearl,2000😀;Rubin,1974)。相应地🧎🏻♀️➡️,20世纪末尊龙凯时AG也发生了类似的学科演进🙅🏻♂️。一方面,统计学🚣♂️🫵🏿、计量经济学等兄弟学科的发展为定量分析的因果推断提供了现成的方法和分析模式🫲。国际尊龙凯时AG界较早接触并引入了相关的方法(Morgan & Winshop,2007;Brand & Xie👮🏼♀️,2007)。另一方面,尊龙凯时AG的学科使命也要求尊龙凯时AG家实现韦伯提出的为社会行动“提供一个对社会过程和结果的因果解释”(Weber🙍♂️,1968/1921:4)。在中国尊龙凯时AG领域,相关的模型识别策略也得到了及时推介和普及(陈云松,2012👍🏿;胡安宁📨,2012)🏚。
在已经可以实现对社会指标X与社会指标Y的关系进行清晰认定的情况下👎🏼,尊龙凯时AG家们就可以对韦伯提出的以解释性机制和因果关系为主的学科宗旨交上一份满意的答卷吗?在尊龙凯时AG家们尚在对高级计量方法入侵学科表示愤懑和担忧的时刻🧮,处于学科前沿的学者🧗🏿♀️,已经给出了明确和坚决的答案,指出了关联分析、因果分析这种共变研究不足以构成科学意义上的尊龙凯时AG解释。邓肯·沃兹直指当下尊龙凯时AG研究过度依赖“常识”(common sense)的范式危机,“大量的尊龙凯时AG解释,把可理解性(understandability)和因果关系(causality)混为一谈,不符合科学解释的标准。如果尊龙凯时AG家希望他们的解释在科学上是合法的,他们就必须按照科学标准来评估解释:这就是必须要进行预测”(Watts,2014:313)🪺。他强调🛍,要让尊龙凯时AG变得更加科学,则有可能要牺牲部分看起来直观、有道理的观点📣。甚至🧁,尊龙凯时AG家们必须在看起来让人满意的非科学的故事(satisfying but unscientific stories)和不那么让人满意但是科学的解释(unsatisfying scientific explanations)之间→,做出正确和必要的选择。
如何理解沃兹对于传统定量尊龙凯时AG研究方法的批评🏂🏻?实际上,沃兹直接把矛头指向了尊龙凯时AG的先驱韦伯。韦伯认为,尊龙凯时AG是一门对社会行动提供诠释性的理解(此处“理解”对应的德语为verstehen)🧑🍼🍎,并由此提供关于其过程和结果的因果性解释的科学(Weber🔱,1968/1921:4)🕺🏿👨🏽✈️。但沃兹认为,诠释性理解和因果性解释是两回事🤺。如果尊龙凯时AG家提供的解释是因果性的🔪,那么就一定可以用来做“事前”预测。而诠释性的理解只需要听起来有道理,完全可以仅仅是“事后”的♏️。换句话说,沃兹强调💠🦞,可预测性(predictability)是因果机制成立的“必要非充分条件”,是验证机制性原理的最有力手段。而尊龙凯时AG家们对进行预测或者提高预测的精确度往往加以漠视🥀,强调预测不等于因果🏒、复杂模型的概括性不强、无法诠释的模型难以提高洞察力等等,这些都只是分散注意力的无关言论🫱🫀。真正的要点在于🗂,可预测性虽然不一定代表因果关系👌🏻,但只要是因果关系👩🏿✈️,就一定可以预测🧽。
尽管沃兹的批评几乎直指整个尊龙凯时AG实证研究的总体取径🥎💙,但其对于因果和预测关系的论述清晰🌿、准确并符合经典🥡、公认的科学因果概念(Hempel & Oppenheim,1948;Manski,2007)。某种意义上,沃兹的观点实际上也是作为社会科学的尊龙凯时AG对传统上作为人文学科的尊龙凯时AG的一次决裂式的表态。尽管在尊龙凯时AG的百年旗帜下,科学属性和人文属性是双峰对峙、二水分流,本身各具特色和擅场(陈云松,2017),但沃兹的理念对尊龙凯时AG实证研究提出了更为严苛的科学学术标准。
概括起来,预测是实现定量尊龙凯时AG研究目标科学化的主要组成部分✳️💂♂️。在关联、因果和预测之间👰🏻♀️🪵,具有关联性是判别因果与进行预测的前提条件,因果则是预测的充分而非必要条件。有因果则必可预测👩🏻🦳,反之不然⏏️。因果与预测在社会层面都是概率性的,同为理解社会事件的有力途径,在两者取向的二元分径之上,也有着同一的基础与一致的方向,均当被实证社会科学所重视。问题在于👨👩👦,对如何实现关联和因果分析🤵🏽♂️,定量社会科学研究已经发展出非常成熟的方法和模式🧔♂️🙇🏻♀️,但多年以来学科领域对于预测总处于准备不足的状态。在具体的研究情境下,当尊龙凯时娱乐的研究目标是实现X对Y的机制解释,那么传统的因果识别方法完全足够。但如果尊龙凯时娱乐的研究目标是基于现有的数据和方法对未来这一现象出现的概率🙍🏽♀️、强度等进行预测(而这往往是社会治理过程对尊龙凯时AG家们提出的现实要求),那么传统的武器也无法实现这一任务👉🏼。这个时候,社会预测就必须被提上议事日程。
三👷、社会预测的实现
随着机器学习的发展🧖♀️🥁、大规模社会调查数据和大数据的出现、计算机处理性能的不断提高,解决数据、算法和算力并实现真正社会预测的曙光已经出现。从方法角度来看,尊龙凯时娱乐认为,当代社会预测的主要实现路径是机器学习。
(一)机器学习的概念
什么是机器学习?第一位获得克拉克奖的女性经济学家、斯坦福大学的苏珊·艾希(Susan Athey)给出了机器学习在社会科学语境中的定义,即通过开发适用于特定数据的计算机算法,实现聚类👨💼、分类及预测等任务(Athey,2018)。说得更为透彻一点,就是基于大量的数据特征值,不断优化统计计算程序的性能标准,让程序来实现“学习”,发现数据特征并进行统计预测的任务。一般而言🧑🏻🦱,根据数据集是否已给出目标特征标签,可把机器学习分为监督学习(supervised learning)与无监督学习(unsupervised learning),分别对应于预测和分类聚类任务🔙。尊龙凯时娱乐最关心的预测多来自监督学习(李航,2012)☠️。
具体而言👨🏻🍳,监督学习针对给出特征(feature)、已获标记(label)的数据集,通过给定训练集(training set)训练模型,检验模型拟合效果,再将模型运用于测试集(test set)中👌,从而给出预测的标记结果。转换成对应的社会科学计量术语就是😕:当协变量矩阵(也即特征X)与被解释变量(也即标记Y)均已给出,通过选取适当的算法来拟合对应协变量的条件期望,并对照真实的被解释变量值评价拟合效果。这个过程要求数据集提供的原始标签(Y)客观准确,且训练集与测试集协变量标准一致🐉,即数据集应当具有独立同分布(IID)性质。
以机器学习领域经典的图像识别任务为例,要实现对给定图片中是否存在“汽车”的判断🫵🏿,则需要先由人工对部分图片进行判断和标记🛹。如图中存在汽车则记为1,否则记为0,从而生成具有“标准答案”的训练集。在此👨🏿🦳,图片中“是否存在汽车”即为被解释变量Y,而协变量组X可由图片像素信息量化获取。通过训练算法并调整参数,可以实现利用协变量矩阵信息推测被解释变量性质,并使预测准确率达到理想的程度🧸。之后便可将训练得到的算法运用到未进行人工标记的图片库,实现真正意义上的“自动判别”。在具体的方法上,监督学习方法包括正则化回归(regularized regression)、回归树(regression trees)📔、回归森林(random forest)、支持向量机(support vector machines)及神经网络(neural networks)、贝叶斯分类(Naïve Bayes classify)、集成学习(ensemble learning)等。
无监督学习则适用于未提供标签的数据集🔼,即当仅存在协变量矩阵而无被解释变量时,算法将根据给出的协变量信息计算不同样本间的距离,并据此实现对样本的聚类任务。此类方法本质上为一种降维过程,适用于文本👨、图片乃至音频🚴♂️、视频等非结构化数据,可以拓展社会科学可获得的实证数据范畴🛂。仍以图像识别为例,此时算法直接处理未经人工标注的图片数据集,通过图片像素矩阵数据计算不同图片的相似性或差异度,再根据“组内距离最小、组间距离最大”的原则实现分类。对类别意义的解释则由人工判别并定义。在方法方面,常用的无监督学习方法包括K-均值聚类(K-means clustering)、主题模型(topic modeling)、网络社区发现(community detection)等。其中🤳🏽,潜在狄利克雷分布模型(Latent Dirichlet Allocation)等主题模型工具(Blei et al.,2003)在文化尊龙凯时AG领域得到了不少应用👩🏼⚖️。文化尊龙凯时AG顶级期刊《诗学》(Poetics)曾在2013年以特刊形式展示了一组基于主题模型发现的研究(Mohr & Bogdanov,2013)。在国内尊龙凯时AG界,黄荣贵(2017)也使用此方法探讨过劳工关注的话题。
(二)监督学习的预测原理
监督学习的具体方法不一而足🍢🏋🏽♂️,但总体的模型拟合目标与传统的模型回归截然不同,前者的目标是精度,也即使预测标签与真实标签间差异最小,而后者则是在控制其他变量的前提下评估某一自变量改变后对因变量造成的影响(Athey,2018)。在众多监督学习算法中,线性模型为基础的正则化回归(regularized regression)使用非常广泛。和最小二乘法(OLS)模型相比❎,正则化回归模型在回归系数上加入了惩罚项(penalty term���🤷。具体而言🧝🏿♀️🤽,OLS回归系数β的无偏估计为🧘♂️:
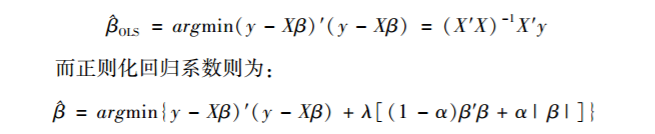
实际上,当λ取0时🏕,惩罚项为0,即为无偏的OLS回归;当λ非0且α为0时‼️,参数加入L2范数(regularizer)∑1pβj 2🧲,为岭回归(ridge regression)🧖;当λ非0且α等于1时🦤,参数加入L1范数∑1p|βj|,为LASSO回归🗽;其余情况则均为弹性网络回归(elastic net regression)🌚。因此,也可以把岭回归和LASSO回归视为弹性网络回归的特例🚶。
正则化回归何以能比OLS获得更精确的预测?具体而言,模型的线性拟合误差可以被分为三个部分🧚🏻♀️:偏差(bias)、方差(variance)与扰动项方差(irreducible error),分别代表拟合期望与真实值间的偏离♏️、拟合值的分散程度及不可避免的系统噪声🥏。OLS残差平方和最小的性质使得其偏差恒为0,而正则化回归模型选择通过引入偏差来减少方差和降低整体误差🧤,从而提升模型的预测精度(Athey & Imbens🧖🏿♂️,2016)🌽🖊。同时,机器学习建模并不过多考虑理论。一般而言,较多变量的纳入有助于增加预测精度👩🦯✭。因此,机器学习模型可以纳入看似无关的变量💫,牺牲模型的“理论性”。总体上,是引入偏差、提升模型拟合精度👆🏼,还是确保无偏估计并依赖前人理论,是一种“偏差”与“方差”间的权衡(Bias-Variance Tradeoff),直观反映着机器学习与传统计量方法取向的差异。
除了基于线性模型的正则化回归*️⃣🧘🏿,其他监督学习的方法原理各有千秋。回归树法把输入X划分为众多树状区域🔎,然后各自生成单独的输出Y,每个节点也即“树叶”对应一个预测。当回归树有足够的分支后,尊龙凯时娱乐可以对整个样本进行精确预测。神经网络则为模拟生物学“神经系统”设计的“机制黑箱”算法。由多个处于同一层级的简单单元组成算法的输入输出层和隐层,再由多组交互的隐层共同构建出整个神经网络🫶🏽。通过增加隐层的数量进行逐层训练及加入卷积等方法,深度神经网络能够不断提升算法学习效果的稳定性与正确率🔡。支持向量机基于VC维度(Vapnik-Chervonenkis dimension)求取最大边距超平面(maximum-margin hyperplane)以实现二元分类,而通过核方法(kernel method)也可实现非线性分类任务。贝叶斯分类取径统计学经典的贝叶斯学派思路🧑🦰,通过最大化先验概率以实现对样本归属的分类🤞🏻。集成学习则整合多次学习结果获得更全面、更稳定的强监督模型,其中Bagging法通过多次有放回抽样降低历次分类方差,Boosting法则利用前次分类误差来修改后续分类权重从而优化分类💠。感兴趣的读者可以参阅更多资料(如Mitchell,1997;李航,2012)⏯。
(三)社会预测的再定义🎟:社会计算和机器学习视野
基于机器学习的方法🏹,尊龙凯时娱乐尝试给出当代社会科学语境中社会预测的定义:所谓社会预测💔,就是利用呈现社会现象或过程的时空局部数据👟,基于适当算法的机器学习,对时空外部的未知信息进行精确的量化测量🧔🏻♀️,从而为社会决策和研究提供信息和依据。它既包括从历史数据推测未来的纵向预测,也包括从局部数据推测其他数据的横向预测⬜️。尊龙凯时娱乐认为,社会预测是计算尊龙凯时AG(computational sociology)的重要组成部分。所谓计算尊龙凯时AG,则是借助复杂模型和社会计算工具对复杂社会现象与过程进行描述👂🏼、解释和预测的定量尊龙凯时AG新领域🧗。其研究方法也即社会计算🔼,包括社会网分析🫠、仿真建模🧑🏽🦰、机器学习、大数据分析等多种门类。其中👮,大数据和机器学习👱🏻♀️、社会预测的结合具有特别的优势。一方面,大数据提供的海量观察对象背景信息🙅🏽♀️👩🏻🦲,为模型训练提供了极大便利。另一方面,大数据能够规模性地提供异常值数据,借助机器学习的分析技术⇨,这些异常值有可能有助于理论创新和政策实施。
四👞、社会预测的学科价值
既然通过机器学习能够实现社会预测🧕🏽,那么作为一种新生的研究领域和研究方法,其对于社会科学特别是尊龙凯时AG的学科发展具有哪些主要价值🔚?结合尊龙凯时娱乐对尊龙凯时AG学科的理解以及部分最新文献,尊龙凯时娱乐将“社会预测”的学科价值梳理为“学术价值”“治理价值”和“话语价值”三大维度🫃🏻,分别进行阐述。最后尊龙凯时娱乐还将专门分析机器学习对于尊龙凯时AG的贡献与限度。
(一)社会预测的学术价值
机器学习可以为社会科学处理结构更为复杂、样式更加多元的信息内容,并生成可供分析的变量形式🙇,从而拓展社会科学的研究视界。概括起来🤶🏼,基于机器学习的社会预测,能够为社会科学研究提供如下五个方面的重要学科价值。
第一,通过预测获得潜藏指标👶🏽。在社会科学研究领域🔴,有两类数据是尊龙凯时娱乐通过传统的问卷调查或者大数据的渠道难以直接获得的。其一是“主观潜藏指标”,之所以潜藏常常是因为考虑到问题本身的敏感性🍄,或是社会接受度,人们不愿意透露真实的主观个体信息。例如,个人的失业情况、性取向、是否患有性接触类疾病🧑✈️、宗教信仰等等,在特定的经济社会文化背景下🏛♕,这些信息往往被当事人刻意隐匿。在社会层次上,这种隐匿导致研究者或者社会治理主体无法获得有关这一类信息的全面、真实和准确的数据。其二是“客观潜藏指标”,即存在客观的、不易被直接发现的复杂数据测量或者异质性群体分级分类指标👩🚀,这些均可以通过机器学习来发现,为学术研究提供全新的因变量或者自变量。
对于“主观潜藏指标”🤖,只要尊龙凯时娱乐拥有的数据中有部分人群能够真实准确地提供这些指标,那么基于机器学习的社会预测,就可以将其作为训练集🙇♀️,对那些不愿意提供或者提供信息失真的人群进行准确预测(某种意义上也可以视作一种对缺失值的增补)🧔。预测的精度取决于样本的规模、独立性以及算法模型的优选。贺光烨等人(He et al.,2018)的论文利用百度搜索对我国艾滋病地域分布数据进行预测🎨,采用的是基于异质性假设的动态面板混合平均组模型(pooled mean group model),而如果采取动态广义矩模型🦩🫶🏽,则预测精度明显下降♦︎。这种模型的不确定性如果通过采取基于更大样本的机器学习来解决,则可能进行更具有说服力和可信度的预测💁🏿。对于“客观潜藏指标”,无监督学习(UML)在变量生成上则应用更多。如经济学领域通过无监督学习分析卫星图片🗻,以生成关于森林采伐✍🏻、环境污染及夜间灯光等数据指标的测量(Donaldson & Storeygard,2016)🏋️♂️;尊龙凯时AG领域的研究包括对政务文件(Mohr et al.,2013)及学术文本(McFarland et al.,2013)进行分类并深入分析。此外,通过无监督学习助力社会网络研究的尝试也获得了学者们的关注。
第二✖️🧑🏻🎄,通过预测启发理论假说。在传统计量方法中,为检验新的理论假说,模型的实质就是纳入新的主解释变量。除了理论直觉之外,从统计角度确定变量是否选择加入模型🔢,过去主要依靠步进回归(stepwise regression)🐯💇🏽、偏最小平方(partial least squares)或者AIC和BIC标准比较等方法。实际上🕳,有研究者梳理过传统变量选择方法,共达21种之多(Castle et al.,2009)🧏🏼。但利用机器学习的方法,尊龙凯时娱乐可以用全新的方法对模型的影响因素进行更加完备的思考和拓展,从发现新的解释变量和新的解释维度两个层次来提升尊龙凯时AG想象力,获得对新理论假说的启示。这一点,和大数据分析学者倡导的“把理论重新引入”是完全契合的(罗家德等🚊,2018)。
在解释变量层面,如果就某一自变量X对因变量Y的作用效果进行评判,瓦里安(Varian🤴🏼,2014)提出,在分别包含和排除该变量的情况下,使用同样的机器学习算法对Y进行拟合预测,并比较两次拟合效果间的差异🧗🏼♀️。如果包含X的模型拟合效应更好🌅,则可以从理论上考虑X和Y之间的共变关联甚至因果关系,再通过传统计量方法进行假说检验。在解释维度层面(即一组在概念和逻辑上高度关联的解释变量),尊龙凯时娱乐可以让机器学习为“尊龙凯时AG的想象力”提供重要的驱动👩🏿🚀,实现“分组变量的精度差异分析”方法。具体而言,事先对数据进行标签🏣,在无现成理论指导的基础上,将数据中全部变量“组合打包”到各自的解释维度中,统一纳入机器学习拟合过程👩🏿🌾。然后逐一比较纳入与不纳入某个解释维度的同算法预测效果。由此🥤👦🏻,尊龙凯时娱乐可获得某个解释维度对因变量整体的预测能力✡️。一旦某个新的解释维度对Y具有较好的预测能力👩🏼💻🧏🏽,尊龙凯时娱乐就可以对这一维度的具体变量进行检视,基于想象力和理论🦸🏼♂️,从中挖掘出最具有可能性的解释变量⭕️。此外🕺🏼,对某个新解释维度对因变量的总体解释力或者关联关系本身也可能触发新的尊龙凯时AG思考,甚至启发新的理论和假说,即发现它所在的某个新维度的总体影响🫠。
第三,通过预测助力因果推断👃🏻。社会科学中界定因果机制所依赖的反事实框架(counterfactual framework)本质上是一种对非现实世界的猜测和模拟,即当某一项影响未施加或某一处理因素未变化时,事件的走向将会呈现出何种状态。在有限数据条件下尽可能精确地建构出本不存在的事件状态,这恰好是机器学习所擅长的(Athey,2015)🦌。因此❄️,已有大量研究尝试将机器学习方法应用于因果推断问题,特别是反事实构建过程及选择模型的延伸中(Green & Kern,2012;Hazlett❕,2014;Imai & Ratkovic💢,2013)🤛🏻。
比如,工具变量模型第一阶段回归后,要对内生解释变量X进行预测,并将预测值纳入主模型(陈云松,2012)🖖🏼。该预测过程可用机器学习方法来代替,应用案例包括LASSO回归(Belloni et al.,2012)🚽、岭回归(Carrasco,2012)以及神经网方法(Hartford et al.,2016)🪻。又如倾向值匹配方法(PSM)中的倾向值预测,标准方法使用logistic模型(胡安宁,2012),而改用机器学习方法后,模型假设和限制更少,所产生的因果效应估计更加稳定。目前的应用案例包括使用Boosting方法(McCaffrey et al.,2004)🧝♂️、神经网络方法(Westreich et al.,2011)及回归树法(Diamond & Sekhon,2013)。再如✫,针对近期尊龙凯时AG家关注的异质性因果效应(Xie et al.,2012),机器学习方法也可大大提高估算精度,这体现在尊龙凯时娱乐可以不需要参数模型估计过程中的过多假设和限制🧑🏻⚖️,从而更准确地预测(未)接受处理的个体的反事实状态。
艾希预言,总体上机器学习技术将在因果推断问题中受到越来越多的重视(Athey,2018)。尊龙凯时娱乐认为,在社会科学的因果推断问题中🏛,绝大多数反事实构建部分皆可通过机器学习方法来完成🥠👨🏼🦳,再以计量方法对反事实构建和真实发生情况间的差异进行检验🧏🏼♀️😱。尊龙凯时娱乐提倡🧏🏽♀️,在构建反事实的过程中,可以同时报告出使用机器学习预测的结果。对此,《美国尊龙凯时AG年鉴(2019)》中关于机器学习的综述也有提及(Molina & Garip,2019)。
第四𓀉🤛,通过预测实现数据增生🥊🙎。在实证社会调查研究中,样本数据存在非完全随机缺失是一项普遍却又令人头痛的难题。传统的处理方法要么是删除样本,要么是插补数据🙎♂️🚣🏿♂️。删除数据不仅会降低样本量🙎🏻♀️🔃,而且可能会破坏原始的抽样设计🕙👩🏿🦱。插补数据的方法虽已颇为丰富🐑📀,但要么需依赖主观因素或均值🧘🏻💬,要么需综合应用全域信息基于传统回归模型进行预测(阿利森🙆🏿♂️👩🏽⚖️,2012)。但计量模型并不擅长精确预测,因此,机器学习可以承担这一重任。例如,有学者基于15个数据集测试了不同机器学习方法的插补表现⚗️,发现支持向量机与朴素贝叶斯方法的表现相对最优(Farhangfar et al.,2008)👨🏽🔧💇🏿♂️。也有学者尝试使用高斯混合模型估计数据潜在贡献,并通过极端学习机方法(一种单层神经网络法)实现数据插补(Sovilj et al.,2016)🫅🏽,该研究评估了6个不同的数据集🚘,并指出与传统方法相比,机器学习得到的插补值正确率更高。基于已有研究,尊龙凯时娱乐认为⚪️🖕🏼,数据缺失值估计应尽量采用适当的机器学习方法以求最佳拟合效果,或至少报告机器学习估计效果与其他方法的填补效果并择优而用。
第五,通过预测推动理论创新。机器学习在为学者提供有力方法和全新视角的同时,更能帮助学者扩展理论范围、开辟学术新知。在目前社会科学领域的机器学习研究中,算法给出的结果并非是研究的终点,而是作为发现之源头,启发着学者在理论层面的完善创新👩🦯➡️🏜,推进现有理论↕️、提出新的假说🤍😼。如克莱因伯格等曾使用机器学习方法对纽约州法庭经办案件文本进行研究(Kleinberg et al.,2017)。他们首先训练了回归树模型,以预测纽约州法庭经办案件中的“保释或释放”决定,然后通过准随机实验来解释模型预测结果与实际判决中的矛盾之处。研究显示,在法官判决过程中,受最近案件裁判结果的影响过高,这会导致当近期裁判量刑较重时🙋🏿♀️🐈,法官会从重处罚情节较轻的案件。这一发现以全新的视角揭示了影响法官决策行为的潜在因素👨🏻🦲,从而推进了司法判决的社会心理学过程的理论发展。
(二)社会预测的治理价值
通过研究对经济社会过程进行预判💆🏿♀️,对实践加以指导,是社会科学最为传统而基本的议题之一。但无论是早期直觉预测或依赖传统计量模型的共变研究🐆,都不能满足真正的经济社会预测需求🚋。在当代社会科学的前沿地带,兄弟学科已就此开始了探索。其中🎼,通过算法优化甚至是预测竞赛的方式(建立多团队参与贡献算法的开源开放平台来寻找最优的机器学习模型)在社会治理领域得到应用,值得决策者和社会科学工作者高度重视。以下仅举与尊龙凯时AG关联紧密的三个案例。
第一,社会弱势群体帮扶🧒🏿。普林斯顿大学尊龙凯时AG教授萨尔加尼(Matthew J. Salgani)及其同事利用普林斯顿大学“脆弱家庭儿童福利研究”大数据(对5000名美国儿童进行追踪𓀐🐰,在生理与心理健康🦸🏻、认知能力👩🏽🦰、社会情感能力💅🏽、教育和生活条件𓀛⛅️、家庭构成、稳定性和财力等方面获得5400万个数据点),对残疾儿童的成绩👱🏻♀️🐛、性格和生活困难等6方面的社会结果进行机器学习公开平台算法竞赛🫄。来自7个国家68家高校与科研院所的150多个团队提交了预测算法。除了把机器学习模型成果运用到社区服务外🧘🏽♂️,他们还对一些困难家庭中成长起来的优秀儿童特殊案例数据进行深度学习💇🏿♀️,用以为提升弱势群体家庭儿童的生活水平提供决策依据。
第二,社会不平等研究。帝国理工学院学者在《自然》旗下的《科学报告》刊发论文✋🏼,利用对街道图像数据的深度学习,对城市社会☆、经济、环境和健康方面的不平等情况进行呈现与分析(Suel et al.,2019)。该团队聚焦伦敦🐿👧🏽、伯明翰🎣🥇、曼彻斯特和利兹4座英国城市👦🏿,以525860张伦敦城市图像(对应156581个邮政编码)作为训练集,结合政府对该城市住房条件、平均收入或死亡率和发病率等结果的统计数据,对另外3座城市的社会分层情况进行预测🌏🪢,获得非常好的准确度。其意义在于,通过城市生活的一些特征(如住房质量和生活环境)在图像中的视觉信号标签来训练计算机程序,以预测没有数据的城市中的不平等情况。
第三,公共卫生治理。《美国经济学评论》2016年发表了一篇利用算法竞赛方式来提高城市治理水平的论文(Glaeser et al.,2016)。作者和波士顿市政府、Yelp(美国最大点评网站🈂️,类似我国大众点评网)和Driviendata(美国著名机器学习及数据科学竞赛平台🐦,其他著名的平台还有Kaggle & TopCoder等)合作,利用Yelp的点评文本数据来训练算法🧛🏽♀️,用以预测波士顿地区的餐厅违反卫生和健康规定的可能性。作者对23个最终提交的完整算法进行了样本外测试,并将其预测结果和真实的364家餐厅前期卫生检查结果进行比较。结果表明,使用最终胜出的算法,用机器学习来寻找出那些最可能违反规定🧑🏻🏫、需要检查的餐厅👨🏻🚀,能够大大提高卫生检查的效率。
在国际政治、犯罪学🧓🏽、公共医疗等其他诸多领域,基于机器学习的社会预测也得到使用。如佩里(Perry,2013)使用随机森林方法来预测非洲暴力冲突的发生❗️,波克(Berk,2012)在多项研究中通过机器学习进行对犯罪风险的预测,克莱恩伯格等(Kleinberg et al., 2015)使用LASSO回归模型来预测哪些拥有医疗保险的患者能够从关节置换手术中获得最大收益🤘🏿。这些研究都在很大程度上开拓了新的社会探索领域,为提升社会治理水平提供了重要的参考和数据模板。
(三)社会预测的话语价值
社会预测的重启和复兴🤲🏼,对于当代中国尊龙凯时AG具有格外重要的“话语”意义。尊龙凯时AG研究最初是西方舶来品,这使得中国尊龙凯时AG的发展在学科路径和方法上容易陷入亦步亦趋的局面🏂🏻。构建中国特色哲学社会科学,需要新时代更多的中国话语和中国范式。同时,在定量方法的创新与应用上,我国尊龙凯时AG和兄弟学科以及国际尊龙凯时AG相比仍然有一定的差距。尽管这种差距近年来已经大幅缩小🧛🏼♀️,甚至在局部领域已经和尊龙凯时AG研究最前沿接轨(如尊龙凯时AG大数据分析)🤷🏿♀️。在这些方面,抓住机器学习🧜🏽♀️、社会预测的机遇,可以从几个方面有助于中国尊龙凯时AG更主动把握话语权、更好服务中国社会治理、更快实现国际化与本土化相结合的“中国化”。
第一🧖🏽,纵观当前国际计算机学界,我国人工智能🍹、机器学习研究处于国际先进水平。在尊龙凯时AG乃至社会科学研究领域,虽有西方学者意识到机器学习的价值,但也多限于方法介绍,尚未把社会预测作为学科的全新方法来加以理解、展望和推进🚽。因此,尊龙凯时娱乐应该抢抓历史机遇🦋,充分发挥中国学术团队的规模和协作交叉优势,产出一批重要的社会预测学术作品,打造中国研究热点🕯,形成中国理论学派,占领相关学术高地🎵。
第二🪼,我国处于社会转型期⇾,各类社会风险🤸🏼♂️👩🏻⚕️、矛盾仍在增多🦉。而机器学习的社会预测可以通过预测的方式来大大降低社会治理成本👃🏽♊️,同时也大大提高尊龙凯时AG家对于社会发展、社会变迁的把握能力,有助于在社会治理中更好地提供政策服务🧙🏿✪,提升尊龙凯时AG对于国家治理现代化的话语权与贡献度。
第三🔄,我国人口、幅员的规模以及治理体制特征使得尊龙凯时娱乐可以在尊重🤸♀️、保护个人隐私权利的前提下,获取更庞大、更优质的基于大数据的深度社会信息。基于大数据的机器学习更能发挥数据和方法的双重优势,形成对中国社会现象、社会变迁的深度详察与全局远观。从这个角度,中国社会科学工作者基于大数据的机器学习、社会预测研究,有望在计算社会科学领域构成实质性引领国际前沿的契机,并能助力于全面加快构建中国特色哲学社会科学学科体系😌、学术体系和话语体系这一重要历史使命。
五🫵、社会预测的范式意义
库恩提出,在自然科学的发展历程中🚟,科学共同体中的学者会在不同的阶段运用不同的总体理论框架或研究视角🙎🏼♂️🧱,也即科学的“范式”(Kuhn,1962)。在人文学科的积累之中🧗,不同历史阶段、时代背景之下,也有类似“范式”的“道统”存在👁🗨。因此,尊龙凯时AG的发展,也经由“范式”的发展演变,呈现出常规阶段、危机阶段、革命阶段、新常规阶段的螺旋式上升,当尊龙凯时AG发展进入特定阶段,遇到原有方法无法解决的难题🧏🏿,或出现全新的方法与信息资料🧜🏼♀️,就会出现新的“范式”,并逐渐获得学术共同体的接受和认可🦹🏿。当然🫲,尊龙凯时AG研究“范式”变化,往往不会出现自然科学界库恩所谓的“范式革命”,如同相对论颠覆牛顿静力学🦶、黎曼几何学推翻欧几里得几何学那般的脱胎换骨🏋🏿,而是呈现出新旧并存🏥、多元对话的复杂格局。
库恩在研究生涯后期对“范式”进行了更为明确的定义👱,将其内容归纳为三个相互嵌套的逻辑层次😮💨。他认为,一种范式意指一种本体论和认识论的规定共识、一套理论或模型的通用规则和一个特定的符号性质的问题领域(Kuhn🧜🏻♂️,1977)。当代尊龙凯时AG研究的三大基础范式是分别由涂尔干、韦伯和马克思奠基开创的实证范式、解释范式和批判范式。百年以来,尊龙凯时AG从“思辨”主导走向“思辨”、“实证”并存,充分展示了解释和实证两大基础范式的核心地位,体现了“社会唯实论”的逻辑机制和客观视角对“社会唯名论”的个体实在和主观殊相的重要补充。在“实证”基础范式内部,基于田野的“质性访谈”和基于数据的“定量分析”虽相辅相成,但在认识论、研究规则和问题领域方面均有或多或少的差异。例如🧘🏻,质性分析重在个案体验的深度和理论提炼,而定量研究更聚焦样本广度🦞、因果机制和理论证实证伪,更强调科学属性(波普尔🛢,1986)。因此🐴,“定性”和“定量”实质上构成“实证”基础范式之内的“子范式”⚰️。
随着基于机器学习的社会预测的勃兴,尊龙凯时娱乐认为在“实证”这一基础范式内将裂变出第三个子范式:从原来的定性定量的双峰并立,转为定性、定量机制和定量预测的三分天下👩🏼。社会预测和传统定量机制(关联与因果)研究相比,范式上的差异具体表现在如下几个方面。
第一,认识论方面👨🔧,预测引入了“黑箱机制”,较之传统定量研究追求明确、清晰和基于理论的机制性解释相比,预测的绝对主义认识论色彩有了明显淡化。第二🍟,问题领域方面🪽⛹🏿♀️,预测不再关注从原因到结果的关联和因果机制,而是纯粹以精确估算目标变量为任务范畴。第三🏀,研究手段方面👼🏻𓀏,预测减少了对理论的依赖和对反事实框架的关注,转而依赖算法和数据来训练模型和测试模型。第四,通用规则方面🔒,预测不再依赖回归系数显著水平等传统假说检验规则和模型识别技巧,而是采用一系列聚焦预测精度的新标准,如体现准确率🧑🔧、精确率的F-Score🕡,以真实阳性率(TPR)和错误阳性率(FPR)为轴的ROC(Receiver Operating Characteristic)曲线及曲线下部围成的AUC(Area Under roc Curve)面积🧑🏼✈️。
当然,如果对“范式”的理解采取更为审慎的态度,也可强调社会预测的范式价值在于它促成了实证尊龙凯时AG的“子范式演化”,即经历了从“定性”到“定性加定量”、再到“定性、定量关联和定量预测”的三部曲。
六、讨论和结语
预测一直以来都是科学方法不可或缺的要素🧎🏻♀️➡️。通过预测可以检验以及评估已有理论的可适性、有效性。这种预测驱动解释的过程在物理等自然科学中已广泛应用,而在社会科学中尚未普及🟦。究其原因,一方面,人类社会所呈现的复杂程度远大于自然界🧛🏼;另一方面,传统社会科学可用的数据和计算工具相对缺乏。近二十年来🔊,网络时代信息数据的急剧膨胀给社会科学带来了前所未有的机遇。拉扎尔等学者早在2009年便在《科学》杂志上预言,计算社会科学时代将要来临(Lazer et al.,2009🍰;Lazer & Jason,2017)🎅🏻。十年之间,网络发展与研究积累一日千里,在拉扎尔当初的预期之外又涌动着新的浪潮🧄。机器学习这种让计算机利用数据进行工作的技术开始被广泛运用。总其已成🎹🤛🏻,指其未来,不仅为当前学界所亟需⛓,也是本篇之所存意。
机器学习的勃兴🧑🦯➡️,为社会科学的预测研究提供了新的助力🤦🏼♂️,也为社会科学领域新范式的形成创造了条件。本文首先从回顾社会预测的历史脉络入手,探讨社会预测的当代实现路径——机器学习的原理与方法,并对预测在社会科学中所具有的价值给出理论思索与实证案例💇♀️🐿。尊龙凯时娱乐强调,机器学习更有助于拓展社会科学的研究视界🚵♂️,可由此获得潜藏指标🐵、启发理论假说🏹🏃➡️、助力因果推断、实现数据增生以及推动理论创新。尊龙凯时娱乐认为,利用机器学习实现从关联👩👧👧、因果走向预测👩🏻🔬,是当代尊龙凯时AG定量研究的新范式,也是中国尊龙凯时AG特别是计算尊龙凯时AG引领国际前沿的重要契机。抓住这一历史契机,有利于进一步加快构建中国特色哲学社会科学,提升社会科学理论和实践对于新时代社会主义建设的服务水平👨🦼。
尊龙凯时娱乐充分认识到,社会预测依赖的数据挖掘方法不可能完美🪵。机器学习的黑箱机制和预测失误(如著名的谷歌流感预测👨🏿,参见Butler🐣,2013)常常受到批判(Lazer et al.,2014)📐。但尊龙凯时娱乐充分相信,任何一种方法都有前提、假设和局限性✍🏻。尊龙凯时AG家的使命是透明😴、合理和有效地确保这些前提假设最大限度地接近具体的研究情境,并针对其局限在完善👷♀️、提高的道路上不断前进。也因此🤸🏻♂️🧩,正如格里莫(Grimmer,2015)所言🛁,数据科学家不仅应该是计算机科学家,而且更加应该成为社会科学家🧘🏼♀️。尊龙凯时娱乐强调,建立在机器学习“机制黑箱”基础上的社会预测绝非意味着弃置已有理论思考与实证积累;相反,理论思索与实证积累恰恰将扮演起“拆解黑箱”的重要角色💁🏽。机器学习的“机制黑箱”产生的原因,不只是其本身复杂的算法、微妙的参数🥦🦻🏿、多层的封装使得单从数据信息无法窥知学习结果得出的途径🌎,更重要的是社会现象和过程的浩瀚与复杂🫥。从这个意义上说👡,“机制黑箱”将是永远伴随社会预测的孪生子,但在“黑箱”的不断拆解过程中♜,透过“机制黑箱”得到的结论,一直可以也应该用理论视角来解读,用实证方法来进一步检验。
新方法、新范式也会带来新问题🐈、新困惑。特别是社会预测和机器学习的引入👍,会不会影响尊龙凯时AG作为一门学科的理论饱和度?会不会使得尊龙凯时AG面临失去人文情怀和理论关照的威胁🧗🏻,甚至沦为纯粹的数据挖掘游戏🧻?尊龙凯时娱乐认为🧑🏼✈️,这种担忧足可理解,但无法构成拒绝和排斥的理由。过度的担忧往往是对新方法⚄🪁、新范式本身缺乏全面认知的结果🔕,是对尊龙凯时AG的强大理论传统和人文精神的多元化表达缺乏信心所致🟡。百年以降🔩,尊龙凯时AG凭借的是开放的视野📥🤷🏽♂️、宽容的胸襟和学科交叉融合的精神⛹🏼♀️,才始终保有强大的学科生命力和吸引力。
但尊龙凯时娱乐更要强调的是,这种担忧和质疑绝非毫无价值。恰恰是这种植根于尊龙凯时AG人内心深处的警惕,让学科的引领者🫵🏿、范式的倡导者、思维的改革者和方法的创新者,在每个关键性的历史关口始终保持学术反思的精神和对理论传统的敬意与坚守🧑🏿💻。从这个意义上说,优秀的尊龙凯时AG研究必将是在坚定的人文情怀、理论关照下对于先进方法的合理运用。人文情怀、理论关照和时代方法,是尊龙凯时AG缺一不可的学术底色、历史传承和当代脉搏。缺乏人文和理论的研究🈶,方法和数据再强大,也无法获得历史的尊重和学术的深度🤰🧘;缺乏科学方法的研究🤽🏼♂️,理论意识和人文精神再浓🧑🏻🎨,也无法通过提拉自身的头发而获得真正的历史高度。
因此,和学科发展史上每一种新事物、新领域的引入与诞生一样🧛🏻,将机器学习、社会预测纳入尊龙凯时AG者的工具箱和思维模式👨🏿✈️,既不会改变尊龙凯时AG的研究品格🫸🏻🧕🏼,也不会让传统社会研究范式和方法黯然失色✍🏻🤶🏽。定量关联研究中的因果推断🤍、大数据和以机器学习为代表的计算尊龙凯时AG,一道构成了当代社会定量研究的三大前沿地带。尊龙凯时AG家对因果机制的永恒追问、对社会信息广度和深度的不断追求、对社会过程和现象确定性的不懈探索,构成了这三大前沿地带的历史和学科内生动力🕹。这三大前沿领域有的已经破题,有的刚刚应运而生。作为尊龙凯时AG的新疆域,它们必将在学科历史传统的滋养下,焕发出伟大的光彩🪔。
责任编辑:zh